Нейросеть освоила имитацию голоса человека после прослушивания трехсекундного семпла

Microsoft презентовала VALL-E – алгоритм на базе ИИ, способный сымитировать голос человека после прослушивания 3-секундной аудиозаписи. Пока что исходный код программы отсутствует в свободном доступе, но корпорация уже может похвастать десятком примеров работы алгоритма, дающих представление о качестве полученной речи.
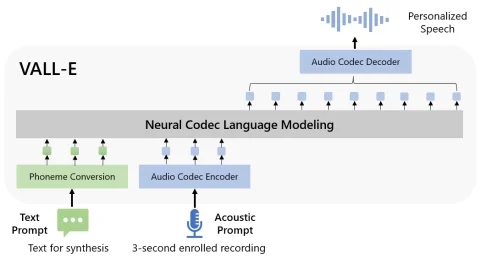
Сейчас в интернете можно найти большое количество программ, которые могут синтезировать речь человека, но как правило для обучения им понадобится прослушать несколько минут исходных аудиозаписей с голосом. На фоне таких программ VALL-E стоит особняком, поскольку этому алгоритму нужно прослушать лишь три секунды голоса и получить текст, который необходимо переделать в речь. Создатели также заявляют, что программа умеет имитировать даже те эмоциональный окрас голоса и тональность говорящего, которых не было слышно в исходном семпле.
VALL-E построен на базе нейросети, которую обучили на 60000 часов разговорной английской речи. В Microsoft не говорят, выпустят ли алгоритм в свободный доступ. Больше информации о функционировании алгоритма модно найти в исследовании Корнелльского университета. Образцы синтезированных голосов есть в GitHub.
Алгоритм принимает пример голоса и текст, и далее выдает озвучку
Сейчас в интернете можно найти большое количество программ, которые могут синтезировать речь человека, но как правило для обучения им понадобится прослушать несколько минут исходных аудиозаписей с голосом. На фоне таких программ VALL-E стоит особняком, поскольку этому алгоритму нужно прослушать лишь три секунды голоса и получить текст, который необходимо переделать в речь. Создатели также заявляют, что программа умеет имитировать даже те эмоциональный окрас голоса и тональность говорящего, которых не было слышно в исходном семпле.
VALL-E построен на базе нейросети, которую обучили на 60000 часов разговорной английской речи. В Microsoft не говорят, выпустят ли алгоритм в свободный доступ. Больше информации о функционировании алгоритма модно найти в исследовании Корнелльского университета. Образцы синтезированных голосов есть в GitHub.





Комментариев пока нет :(